「ノンプログラマーでもできるpythonでwebサイト構築①」の続きです。
今回は、サイトのデータ収集部分、スクレイピングについて紹介していこうと思います。スクレイピングにはPythonのライブラリである「Requests」と「Beautifulsoup」を使用しています。「Requests」はHTTPライブラリと呼ばれるもので、簡単に言えばホームページを見るのと同じようにPythonからインターネット経由でホームページに接続してくれるイメージです。以下の通り簡単に接続ができてHTML形式でデータが得られます。
1 2 3 4 5 6 |
import datetime import re import urllib.request import webbrowser import requests from bs4 import BeautifulSoup |
1 |
html = urllib.request.urlopen("https://www.jpx.co.jp/markets/derivatives/participant-volume/index.html") |
先物手口情報はJPXのサイトから取得します。いきなりですが筆者が最初に躓いた点がここです。サイトをご覧いただければわかるのですが、エクセルが4つ掲載されていて、エクセルのURLが毎日変わるのです。いつも同じであれば、直接エクセルのアドレスを指定すればよいのですが、そういう訳にも行かず、次の手順を踏んでいます。
- urllib.requestでエクセルが掲載されるページのHTMLを取得
- 取得したHTMLからBeautifulsoupを使って、該当の4ファイルのURLを特定
- requestを使って4ファイルをダウンロード
1 2 3 4 5 6 7 8 9 |
soup = BeautifulSoup(html, "html.parser") # "lxml") now = datetime.datetime.now() date = now.strftime("%Y%m%d") night = soup.find("a", href=re.compile(date + '_volume_by_participant_night.csv')).get('href') night_j = soup.find("a", href=re.compile(date + "_volume_by_participant_night_J-NET.csv")).get('href') day = soup.find("a", href=re.compile(date + "_volume_by_participant_whole_day.csv")).get('href') day_j = soup.find("a", href=re.compile(date + "_volume_by_participant_whole_day_J-NET.csv")).get('href') |
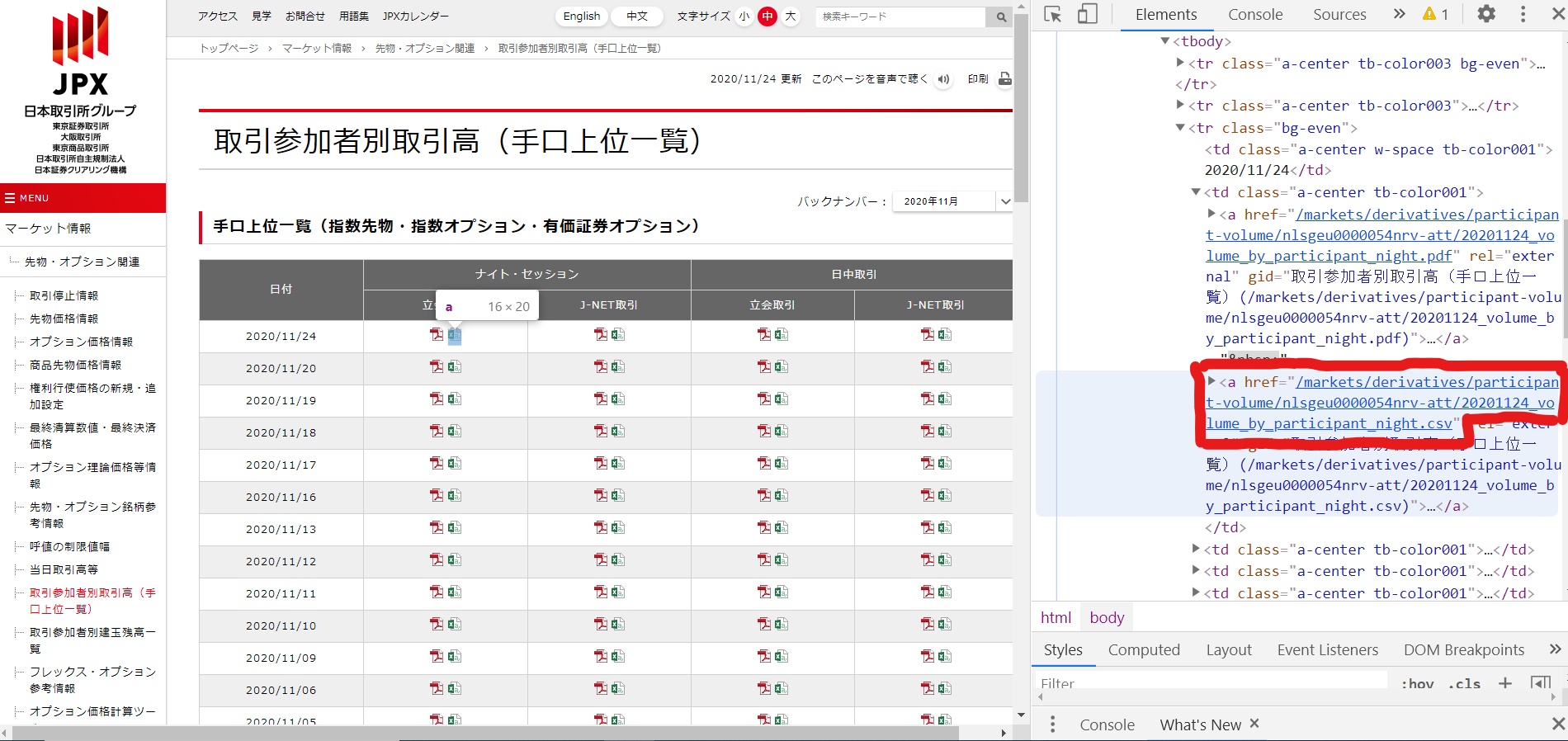
初めにsoupというBeautifulsoupオブジェクトを作成します。そしてsoupからHTMLのaタグの中を条件検索して該当するhrefを取得しています。取得したいデータがどのタグに含まれているのかなどは事前にサイトから右クリック検証で該当部分を調べておきます。(ブラウザはChromeを推奨)
1 2 3 4 5 6 7 8 9 10 11 12 |
urlnight = "https://www.jpx.co.jp" + night urlnight_j = "https://www.jpx.co.jp" + night_j urlday = "https://www.jpx.co.jp" + day urlday_j = "https://www.jpx.co.jp" + day_j for download_url in [urlnight, urlnight_j, urlday, urlday_j]: file_name = download_url.split("/")[-1] r = requests.get(download_url) if r.status_code == 200: f = open(file_name, "wb") f.write(r.content) f.close() |
あとは各URLを設定して、requests.getで一つずつファイルをダウンロードしていってます。このサイトでは先物手口以外にも日経平均株価や建玉データ、ETF価格など様々なデータをこのスクレイピングを用いて取得しています。すべては紹介しませんが、上記のやり方をベースに少しアレンジするだけで可能となっていますので、ぜひチャレンジしてみてください。
サイトの仕組み的に次の工程は、ダウンロードしたデータを扱いやすいように加工して、データベースに溜め込むという工程ですが、加工は地味な作業をひたすら行うだけで、特に気づきはないかと思いますので、次回の記事はデータベースへの保存のあたりを掲載しようと考えています。
はじめまして!
建玉を調べていてたどり着きました。
ノンプログラマーでこんな凄いサイトを作り上げたなんて、心より尊敬します。
半年も没頭される集中力も凄いです。
私は株もプログラムも初心者で、いつかpythonでこんな事をしてみたいという理想を
実現されているので非常に羨ましいです。
私も挑戦してみたくなりました。
更新楽しみにしています!
こんにちは!Pythonにもご興味がおありなんですね!
機械学習はもちろんの事、集計の自動化やWebページ更新まで色々な事ができるので、非常に面白いです。
ぜひチャレンジしてみてください!
PS 只今仕事が少し忙しく更新滞っていますが、落ち着いたら続きも書いていきますね!