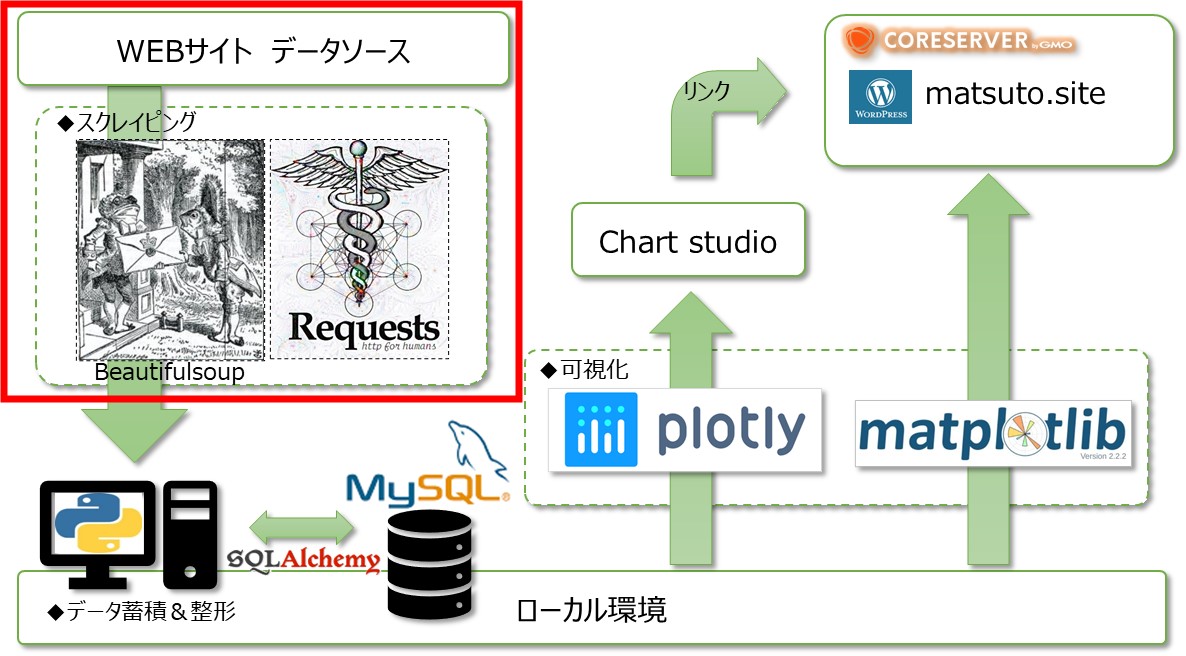
GoogleTrendsのデータをPythonで分析するパート2です。Pythonという意味ではパート➀とほぼ内容は同じです。今回は最近再度話題になっている仮想通貨のデータを取得して分析してみますという内容です。足元のビットコイン価格は200万円あたりで、2017年のビットコインバブルの高値圏で推移しています。果たして足元の価格上昇は2017年のバブルの様に崩壊するのか。それともまだまだこれからなのか。Google検索のデータによりバブル感、過熱感を推し量ろうと思います。
分析方法
Pythonのライブラリ「pytrends」を使って分析します。
まずはライブラリのインポート。
|
1 2 3 |
import pandas as pd import matplotlib.pyplot as plt from pytrends.request import TrendReq |
取得したデータをデータフレームとして扱うための「pandas」。可視化ライブラリの「matplotlib」。
そしてGoogleトレンドからデータを取得するAPI「Pytrends」。
続いてビットコイン価格を取得しておきます。データはInvesting.comでダウンロードできます。
|
1 2 3 4 5 6 7 |
df_price = pd.read_csv("bitcoin_price.csv") df_price.columns = ["date","price","始値","高値","安値","出来高","前日比%"] df_price['date'] = pd.to_datetime(df_price['date']) df_price = df_price.set_index("date") df_price = df_price.drop(["始値","高値","安値","出来高","前日比%"],axis=1).astype(int) df_price = df_price.sort_index() df_price.plot() |
|
1 2 3 |
kw_list = ["Bitcoin"] pytrends = TrendReq(hl='en-US', tz=360) pytrends.build_payload(kw_list, cat=0, timeframe='today 5-y', geo='', gprop='') |
続いて調べたい検索ワードをkw_listとしてリスト形式で指定します。今回はBitcoinとしています。続いて、検索条件を指定します。先ほどの検索ワードとしてkw_list。timeframeで期間の指定。今回は直近5年。geoで国を指定しますが、世界のデータを取得するため空白で指定しています。続いて、取得したデータをデータフレームとして格納します。
|
1 2 3 4 5 6 7 8 9 10 |
fig = plt.Figure(figsize=(10,5)) ax1 = fig.subplots() ax2 = ax1.twinx() ax1.plot(df_5y.index, df_5y.iloc[:,0], color="r") ax1.legend(["Google Trends"], loc="upper left") ax2.plot(df_price.index, df_price.iloc[:,0]) ax2.legend(["Bitcoin Price"], loc="upper right") fig |
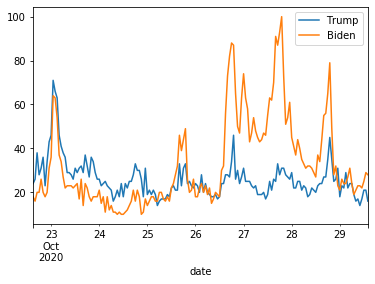
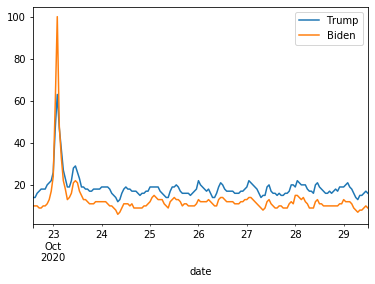
続いて、Google検索のデータとビットコイン価格をグラフ表示します。ここではmatplotlibを使用して2軸のグラフを描いています。
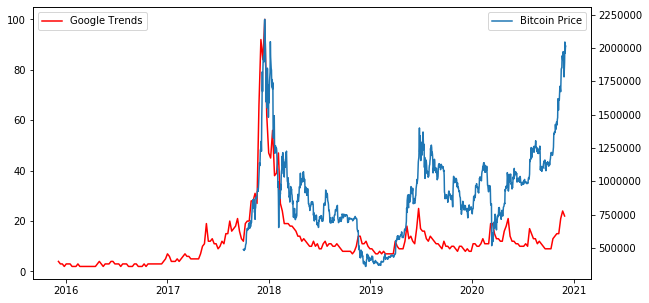
結果は図のようになりました。ビットコイン価格は2017年末の価格に迫りつつあるのに、Google検索数は当時の2割程度。チャートには過熱感はありますが、世の中盛り上がりに欠けています。これはまだまだバブルではありません。だって注目しているのは一部の人だけですから。これは、、価格崩壊するのはまだ先と考えてよいのではないでしょうか。
今後、2017年の様に誰もが注目することが再び起こるとするならば、ビットコインの価格は高値更新がされる事でしょう。
※この記事は、ビットコインへの投資を推奨するものではありません。筆者は仮想通貨を全くやっておりませんので、責任は負いかねます。