いよいよ米大統領選。
トランプ対バイデンです。
マーケットはバイデン大統領を織り込みに行っているなどと言われていますが、果たして本当にそうなのか。いやそうなんでしょうけど、、どんでん返しはないのか。疑ってしまいます。
Google検索のデータを見てみましょう。ということでPythonで分析してみます。
※この記事は大統領選の予想をするというよりは、Google検索のデータをPythonでいじってみましたという内容が主です。大統領選が気になるという方は、結果の部分だけお読みください。
分析方法
Pythonのライブラリ「pytrends」を使って分析します。
まずはライブラリのインポート。
1 2 3 4 |
import pandas as pd import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties from pytrends.request import TrendReq |
取得したデータをデータフレームとして扱うための「pandas」。可視化ライブラリの「matplotlib」と日本語表示用の「FontProperties」。
そしてGoogleトレンドからデータを取得するAPI「Pytrends」。
1 2 3 4 |
kw_list = ["Trump","Biden"]<br />pytrends = TrendReq(hl='en-US', tz=360) pytrends.build_payload(kw_list, timeframe='now 7-d', geo='JP') df_World = pytrends.interest_over_time() df_World.iloc[:,:2].plot() |
続いて調べたい検索ワードをkw_listとしてリスト形式で指定します。今回はトランプとバイデンとしています。続いて、検索条件を指定します。先ほどの検索ワードとしてkw_list。timeframeで期間の指定。今回は直近7日間。geoで国を指定します。続いて、取得したデータをデータフレームとして格納し、グラフで表示します。
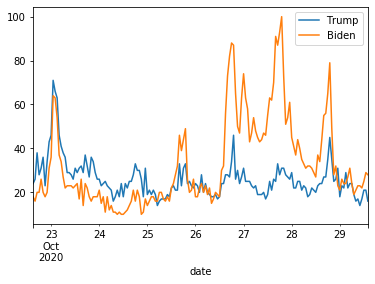
下馬評通り足元ではバイデンの方が多く検索されて盛り上がっていることがわかります。
ただ、こちらは日本での検索結果。続いて米国の検索データも確認します。先ほど"JP"で指定した部分を"US"に変更するだけです。
1 2 3 4 |
kw_list = ["Trump","Biden"] pytrends.build_payload(kw_list, timeframe='now 7-d', geo='US') df_US = pytrends.interest_over_time() df_US.iloc[:,:2].plot() |
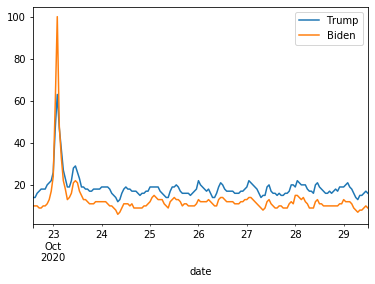
ん…?23日にバイデン優位となって以降トランプの方が上回ってます。そもそもの検索数が現大統領の方が多いというのはありますが、それにしても盛り上がってすらいないようです。続いて期間を3か月にして見てみます。"now 7-d"を"today 3-m"に変更して実行します。
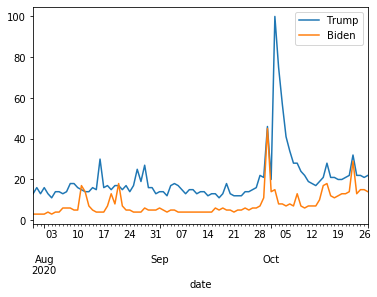
こう見るとバイデンがじわじわと注目を浴びてきているのはわかります。ただトランプも負けてない。
続いて、大統領選は州ごとの選挙ですので、絶対数で見るよりも州ごとにみましょうという事で、州別に検索数を確認してみます。こちらは時系列にも取れますが、若干面倒なので、7日間のデータを一括で取得します。
1 2 3 |
df_region = pytrends.interest_by_region(resolution='COUNTRY', inc_low_vol=True, inc_geo_code=False) df_region = df_region.sort_values("Trump") |
州別のデータをデータフレームとして格納して、トランプの検索比率大なる順でソートします。
1 2 3 4 5 6 7 8 9 10 |
FontPath = "meiryo.ttc" jpfont = FontProperties(fname=FontPath, size=14) fig = plt.figure(figsize=(10,20)) plt.barh(df_region.index, df_region.iloc[:,0]) plt.barh(df_region.index, df_region.iloc[:,1],left=df_region.iloc[:,0],) plt.yticks(range(len(df_region.index)), df_region.index, fontproperties=jpfont) plt.title("地域別Google検索ワード比率(1-week)",fontproperties=jpfont) plt.legend(labels=kw_list) plt.show() |
取得したデータには日本語表記で州名が記載されているので、フォントを設定します。※jupyternotebookのディレクトリ内にmeiryo.ttcファイルをコピーして置いてあります。
続いて、matplotlibでfigureサイズを設定して、横バーグラフを描きます。最初にトランプの比率、続いてバイデンの比率。
最後に州名をy軸に、タイトルを設定、凡例を設定して終了です。
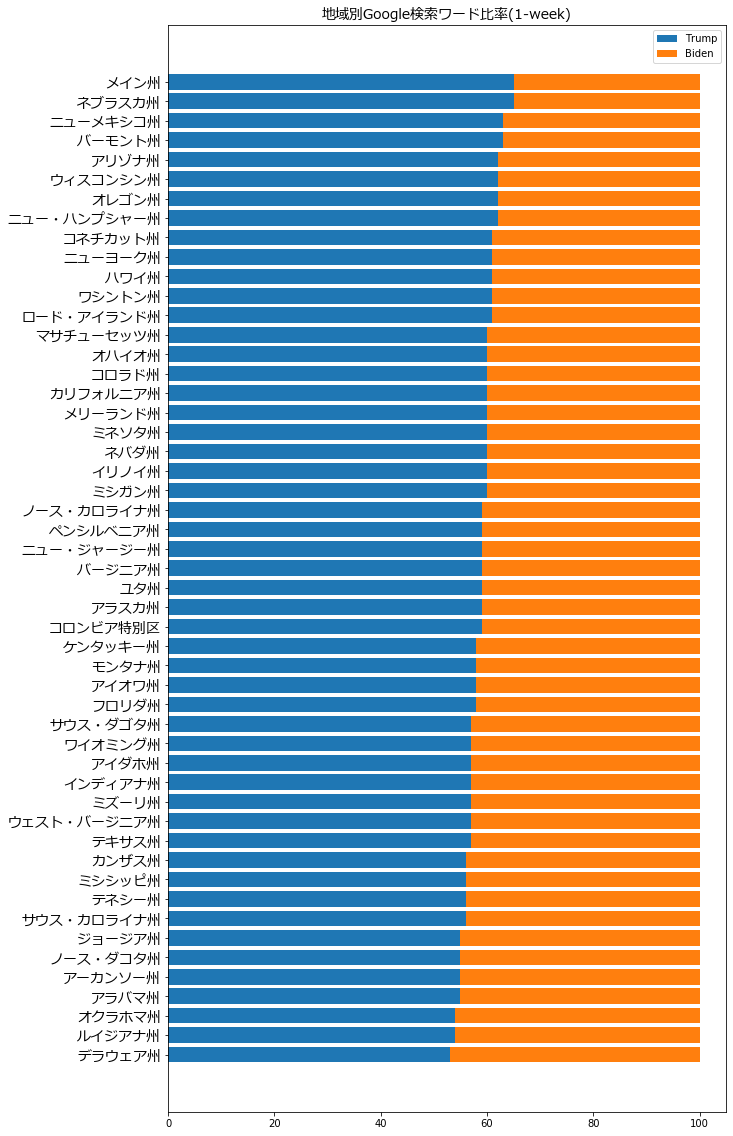
おー。州ごとに出た。ふむふむ全体的にトランプの方が多いけど、やはり州によって違いますねー。
って、ん…?民主党の州がトランプを検索、共和党の州がバイデンを検索…
ふむ、なるほど。全然わからない。
自分の感覚的に応援しない人の事なんて調べる気にならないけど違うのか。
ちょっと州ごとのデータは見方がよくわからないけど、時系列データなんか見るとあっさり決まらないような気がしますね。
更に郵便投票などもありでグダグダ決まらず株価軟調。そこが仕込みどきですかねー。バイデン大統領決定で金利高、株やや高、ドル安なんてことを想定しておきますか。